# 数据集
# Classification datasets results
# What is the class of this image ?
Discover the current state of the art in objects classification.
- MNIST (opens new window)
- CIFAR-10 (opens new window)
- CIFAR-100 (opens new window)
- STL-10 (opens new window)
- SVHN (opens new window)
- ILSVRC2012 task 1 (opens new window)
# MNIST who is the best in MNIST ?
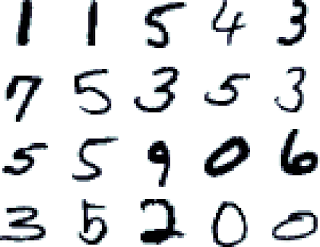
# MNIST (opens new window) 50 results collected
Units: error %
Classify handwriten digits (opens new window). Some additional results are available on the original dataset page (opens new window).
Something is off, something is missing ? Feel free to fill in the form (opens new window).
# CIFAR-10 who is the best in CIFAR-10 ?

# CIFAR-10 (opens new window) 49 results collected
Units: accuracy %
Classify 32x32 colour images (opens new window).
Something is off, something is missing ? Feel free to fill in the form (opens new window).
# CIFAR-100 who is the best in CIFAR-100 ?

# CIFAR-100 (opens new window) 31 results collected
Units: accuracy %
Classify 32x32 colour images (opens new window).
Something is off, something is missing ? Feel free to fill in the form (opens new window).
# STL-10 who is the best in STL-10 ?

# STL-10 (opens new window) 18 results collected
Units: accuracy %
Similar to CIFAR-10 but with 96x96 images. Original dataset website (opens new window).
Something is off, something is missing ? Feel free to fill in the form (opens new window).
# SVHN who is the best in SVHN ?

# SVHN (opens new window) 17 results collected
Units: error %
The Street View House Numbers (SVHN) Dataset (opens new window).
SVHN is a real-world image dataset for developing machine learning and object recognition algorithms with minimal requirement on data preprocessing and formatting. It can be seen as similar in flavor to MNIST(e.g., the images are of small cropped digits), but incorporates an order of magnitude more labeled data (over 600,000 digit images) and comes from a significantly harder, unsolved, real world problem (recognizing digits and numbers in natural scene images). SVHN is obtained from house numbers in Google Street View images.
Something is off, something is missing ? Feel free to fill in the form (opens new window).
# ILSVRC2012 task 1 who is the best in ILSVRC2012 task 1 ?

# ILSVRC2012 task 1 (opens new window)
Units: Error (5 guesses)
1000 categories classification challenge (opens new window). With tens of thousands of training, validation and testing images.
See this interesting comparative analysis (opens new window).
Results are collected in the following external webpage (opens new window)
Last updated on 2016-02-22.
© 2013-2016 Rodrigo Benenson.
Built using middleman (opens new window) and bootstrap (opens new window).