# 深度定位:深度神经网络的故障定位
DeepLocalize Fault Localization for Deep Neural
# 摘要
深度神经网络(dnn)正在成为大多数软件系统不可或缺的一部分。之前的研究表明,深度神经网络存在缺陷。不幸的是,由于缺乏对模型行为的理解,现有的调试技术不支持定位DNN错误。整个DNN模型呈现为一个黑盒子。为了解决这些问题,我们提出了一种方法和工具,可以自动确定模型是否存在错误,并识别DNN错误的根本原因。我们的关键见解是,可以分析在层之间传播的值的历史趋势,以识别故障,并定位故障。为此,我们首先启用深度学习应用程序的动态分析:将其转换为命令式表示,或者使用回调机制。这两种机制都允许我们插入探针,当DNN在训练数据上进行训练时,可以对DNN产生的痕迹进行动态分析。然后,我们对轨迹进行动态分析,以识别导致错误的故障层或超参数。我们提出了一种识别根本原因的算法,该算法通过捕获任何数值误差和在训练过程中监测模型,并找到DNN结果上每个层/参数的相关性。我们从Stack Overflow和GitHub收集了一个包含40个错误模型和补丁的基准测试,这些模型和补丁包含深度学习应用程序中的实际错误。我们的基准可以用来评估自动调试工具和修复技术。我们使用这个DNN bug-and-patch基准测试评估了我们的方法,结果表明我们的方法比现状-实践的Keras库中使用的现有调试方法要有效得多。对于34/40个案例,我们的方法能够检测到错误,而Keras提供的最佳调试方法检测到32/40个错误。我们的方法能够定位21/40个bug,而Keras无法定位任何错误
# Ⅰ.介绍
深度神经网络是一类机器学习算法,近年来由于它们在挑战传统算法技术的任务中取得了显着的成功而获得了显著的普及。深度神经网络可以被认为是一个图,其中的节点(称为神经元)是具有可调权重的函数。深度神经网络的神经元是分层组织的,边缘将输出从一个神经元传递到下一层的神经元,最终传递到最后一层,即输出层。在训练步骤中,每个训练输入通过网络产生输出。这个输出与预期输出进行比较。实际输出和预期输出之间的差异,使用一个称为损失函数的函数来测量,然后使用一个称为反向传播的过程来调整层中神经元的权重。dnn在各种软件系统中被用来做决策。因此,深度神经网络的软件工程变得至关重要。
为了帮助DNN在软件系统中的集成,许多开发人员已经制作了工业强度的库和框架,如TensorFlow [1], Cafe [2], MXNet [3], PyTorch [4], Theano[5]和Keras[6],以帮助程序员设计可靠的深度学习应用程序。最近的研究表明,使用深度神经网络的应用程序存在bug[7] -[9]。同一组研究人员也研究了DNN的修复策略[10]。Zhang等人[8]描述了在检测和定位DNN模型中的错误方面的挑战和局限性,并指出当前的方法在某些时候不能有效地检查模型的状态,就像常规程序一样。Islam等人观察到,与传统的bug修复模式相比,DNN bug修复模式具有独特性,并且DNN bug定位是开发者修复bug时面临的主要挑战之一[10]。
尽管有越来越多的软件调试技术,如自动错误修复[11],[12],故障定位[13],[14],增量调试[15]和切片[16],但这些技术仍然不适用于识别DNN模型中的错误,以及识别导致模型中特定层问题的错误语句。常规软件程序和深度神经网络模型在故障和故障检测方面有着根本的不同。例如,常规软件程序是通过比较实际输出和预期输出来测试的。如果实际输出与预期输出不匹配,那么我们认为程序有bug。
另一方面,基于dnn的软件结构复杂,它是从训练数据集中学习的。如果DNN在训练过程中产生了错误的分类,我们称之为失败案例,这并不一定是DNN包含错误,因为DNN模型不能保证100%正确的分类。
此外,常规程序的逻辑是根据控制流来表示的,而DNN程序使用神经元和不同类型的激活函数之间的权重,出于类似的目的。这些差异使得部署dnn的软件的调试和测试具有挑战性。
传统的调试实践使用诸如打印语句、断点和跟踪失败测试用例之类的辅助工具。这些手动调试过程需要开发人员花费很长时间和精力[17]。研究人员提出了几种自动故障定位技术[13],[18],[19]。这些技术用于定位根本原因并了解故障状态。不幸的是,目前的自动故障定位技术不能直接应用于深度神经网络,因为现有技术无法识别DNN中意外行为(称为故障)的合理和独特的根本原因。
为了克服这些挑战,本文引入了一种基于白盒的深度神经网络故障定位技术。我们的方法需要DNN模型的源代码和训练数据。给定源代码,我们的方法支持DNN的动态跟踪收集。我们提出两种技术。第一种技术受到[20]的启发,将代码翻译成一种中间形式,我们称之为深度神经网络的命令式表示。命令式表示的目的是确保DNN的内部状态是可观察的,因此我们的方法使用白盒方法。这种向命令式表示的转换允许我们插入探针,当DNN在训练数据上进行训练时,可以对DNN产生的痕迹进行动态分析。第二种技术使用一种新的回调机制来插入同样达到相同目的的探针。然后,我们对轨迹进行动态分析,以识别导致错误的故障层或超参数。我们还提出了一种算法,通过捕获任何数值误差和在训练期间监测模型,并找到DNN结果上每层/参数的相关性来识别根本原因。
我们已经将我们的方法作为广泛使用的Keras库的扩展来实现,用于深度学习。为了评估,我们从Stack Overflow和GitHub收集了一个包含40个错误模型和补丁的基准,这些模型和补丁包含深度学习应用程序中的实际错误。我们的基准可以用来评估自动调试工具和修复技术。
我们将我们的方法与Keras库中的三种内置调试机制进行比较,Keras库是DNN库中最先进的。这些机制是TerminateOnNaN(), earlystop (' loss ')和earlystop (' accuracy ')。我们使用这个DNN bug-and-patch基准测试对我们的方法进行了评估,结果表明我们的方法比现状-实践的Keras库中使用的现有调试方法有效得多。对于34/40个案例,我们的方法能够检测到错误,而Keras提供的最佳调试方法检测到32/40个错误。
我们的方法能够定位21/40个bug,而Keras无法定位任何错误。综上所述,本文做出了以下贡献:
- 我们提出了DNN的第一种故障定位方法,包括用于收集动态轨迹的回调和翻译机制以及定位算法。
- 我们用40种不同类型的bug模型从Stack Overflow a中构建了一个DNN bug和补丁基准测试,这个基准是评估我们方法的基础。我们也希望它可以为其他研究人员验证他们的调试和修复工具。此基准测试可从GitHub获得[21]
- 结果表明,该方法可以有效地识别出40个bug模型中的34个,并确定了其中21个bug模型的根本原因。
# Ⅱ. 例子
清单1显示了Stack Overflow[22]中的一个简单示例。密集层是深层神经网络中的一层,其中每个神经元都连接到下一层的神经元。这个DNN在训练期间没有学习,在帖子中,开发人员问为什么模型达到了低准确率。这个深度神经网络有两个问题。首先,它处理一个分类问题,因此在第6行应该使用categorical_crossentropy作为损失函数,而不是使用mean_squared_error。其次,用户没有在第2行和第4行为前两层添加激活函数。
1 model = Sequential() # 构造一个顺序模型
# 添加一个密集输入层
2 layer1 = Dense(30, input_shape=input_shape, kernel_initializer=RandomNormal(stddev=1), bias_initializer=RandomNormal(stddev=1))
3 model.add(layer1)
# 添加一个密集隐藏层
4 layer2 = Dense(10, kernel_initializer=RandomNormal(stddev=1), bias_initializer=RandomNormal(stddev=1))
5 model.add(layer2)
# 编译模型以将其转换为图形形式
6 model.compile(optimizer=SGD(lr=3.0), loss= ' mean_squared_error ', metrics=[' accuracy '])
# 训练该模型
7 model.Fit (x_train, y_train, batch_size=10, epochs=30, verbose=2)
Keras提供了一组回调方法[23],为开发人员提供有关培训过程内部状态的信息。具体来说,我们可以使用TerminateOnNaN()来监控损失,并在损失变为NaN时终止训练。我们可以使用earlystop()来监控丢失或准确性,如果没有改进就停止。我们可以将回调方法作为参数传递给fit()方法。对于清单1,当使用TerminateOnNaN()、earlystop (' loss ')、earlystop (' accuracy ')和三个Keras方法的并集时,训练分别在1.20、12.21、34.90和1.16秒后终止。一旦训练停止,Keras打印epoch和迭代数。不幸的是,这些信息并不能回答开发人员的问题和指出哪个层或超参数阻止了模型的学习。
我们的方法报告程序在使用我们的工具和使用我们的回调函数后分别在0.14秒和2.14秒后出现错误。此外,我们报告该漏洞位于第2层第4行的反向传播阶段。因此,该消息在第2层的参数中给开发人员提示了问题,由于消息的描述表明了问题的阶段,开发人员可以快速确定导致问题的先前计算,即我们示例中的损失函数。与Keras中现有的方法相比,我们的故障定位使用了更少的时间,并提供了一个报告,说明错误所在的层。
# Ⅲ. 动态轨迹收集、故障检测和定位算法
# A.概述

左边——准备DNN模型来收集动态轨迹。提出了两种机制:①将深度学习程序转化为命令式程序[20],[24]。探针被插入到这个命令式程序中,以捕获和保存模型变量,如权重,训练期间的学习率梯度。②使用回调机制,并在模型训练期间传递一个专门的回调方法作为参数(传递给fit()方法)。这个自定义回调函数允许开发人员捕获并保存模型变量。我们在前馈和后向传播阶段记录键值。在训练过程中,进行在线统计分析,将程序的状态与我们定义的错误条件进行比较。
最后,我们报告程序是否包含错误,以及在哪个层和阶段存在阻碍学习的错误。
# B.模型制备
直接分析该深度学习程序是很困难的,因为DNN库提供了黑盒api,并且很难在训练期间跟踪重要的值。要使用我们的方法,开发人员要么编写额外的代码来在fit()函数中进行DNN训练,要么将代码重写为命令式形式。
对于第二种方法,我们根据机器学习文献[25]-[27]和Keras文档[28]确定了Keras库API列表,这些API对于训练和实现这些API调用的模型/简化版本很重要。将探针插入到这些库模型中,以便分析可以观察dnn在训练过程中的内部行为。
基于回调的动态跟踪收集方法是通过覆盖keras.callback .callback类来实现的。由于我们的工作重点是在训练阶段进行监控,因此我们覆盖了名为(on_train_batch_end(self, batch, logs=None))的方法。这个被重写的方法在每批训练之后调用算法1。要使用此方法,开发人员需要将此自定义回调函数作为参数传递给fit()函数。
从 Keras 代码到 Imperative 程序的转换
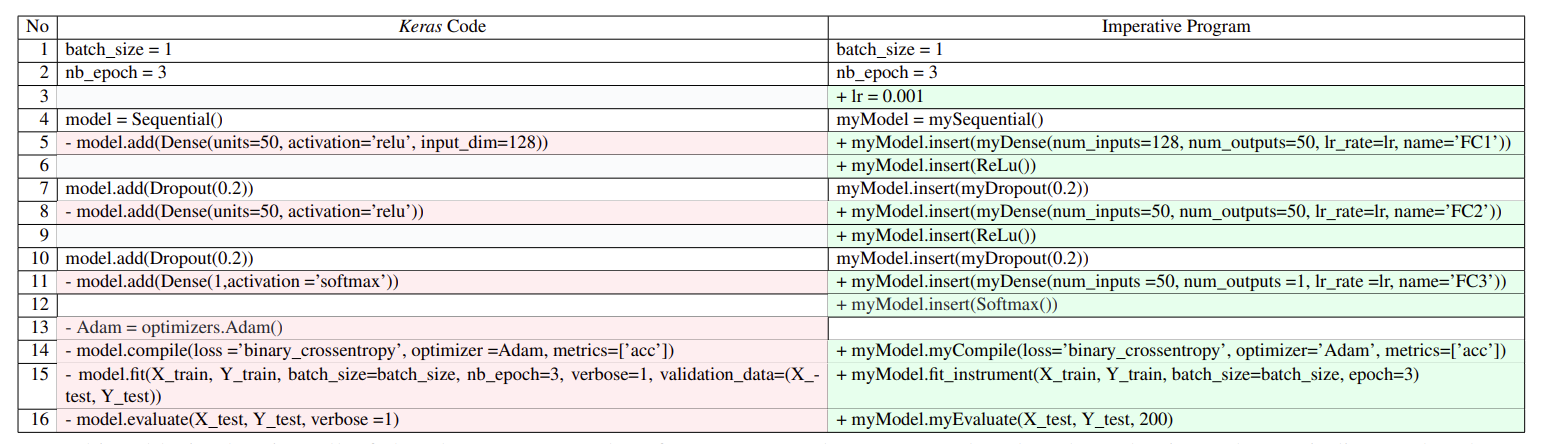
本表显示了从 Keras 代码转换到 Our 工具代码的所有更改。每一行中的颜色表示更改类型: 绿色 + 添加新行,红色 - 删除现有行
第二种势在必行的方法,如左侧表1所示,为了构建训练模型,DNN程序通常从创建顺序模型(第4行)开始,然后添加所有层(第5-11行)和优化(第13行),最后在第14-15行调用compile和fit。在右边,我们展示了使用库模型的命令式程序。首先,第1、2、7和10行没有改变。其次,第5、8和11行显示了Dense层的转换。在我们的代码中,我们为层添加了一个名称,例如,查看name =“FC1”,以便我们可以报告故障位于哪一层。我们在fit函数(第15行)中插入了仪表来观察模型变量。
目前,我们的翻译工具支持Dense, Dropout, Maxpooling, Convolution, BatchNormalization和Padding图层。此外,它还支持流行的优化方法、损失和激活函数。从DNN程序到使用我们库模型的程序的转换目前是手动完成的。Keras库正在快速发展,产生了大量的版本[10]。由于库的版本控制和频繁更改的API签名,我们的工具很难和Keras库保持兼容性。
# C.方法
深度神经网络的训练有两个阶段:前馈和反向传播。在前馈阶段,我们观察和监控:(1)训练数据包括输入和标签;(2)应用正演函数后的结果;(3)应用激活函数后的结果;(4)损失值;(5)精度。在训练期间的每次迭代中收集所有值。
第二阶段是反向传播,根据前馈阶段得到的误差调整权值。反向传播使用梯度下降法来更新权值并使误差最小化。它从输出层开始,并重用输出层的结果来计算前一层的梯度,直到它到达输入层。在反向传播期间可以应用不同的优化。在反向传播阶段,我们可以观察和监控:(1)权值的更新,(2)偏置值的更新,以及每层应用梯度下降后的∆权值。
检测被插入到fit()函数中,我们为对Keras fit()函数建模而实现了fit()函数。当DNN程序在训练期间运行时自动执行。
# D.统计分析以侦测可疑行为
接下来,我们讨论了在训练过程中检测DNN可疑行为的统计分析方法。我们分析了三个变量:学习率、输入数据和激活/损失函数。
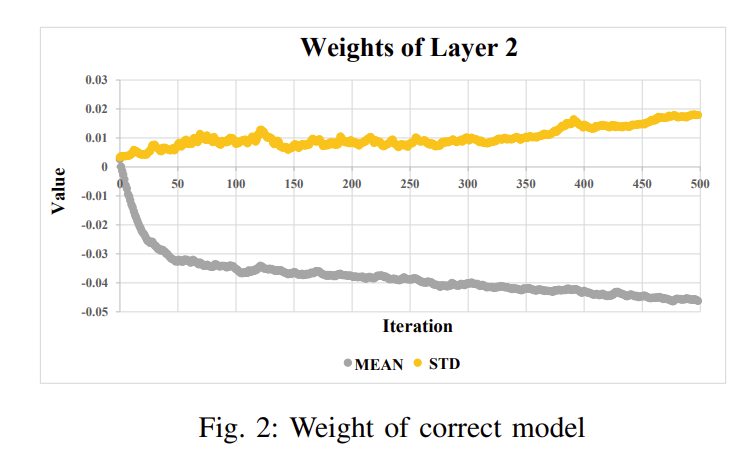
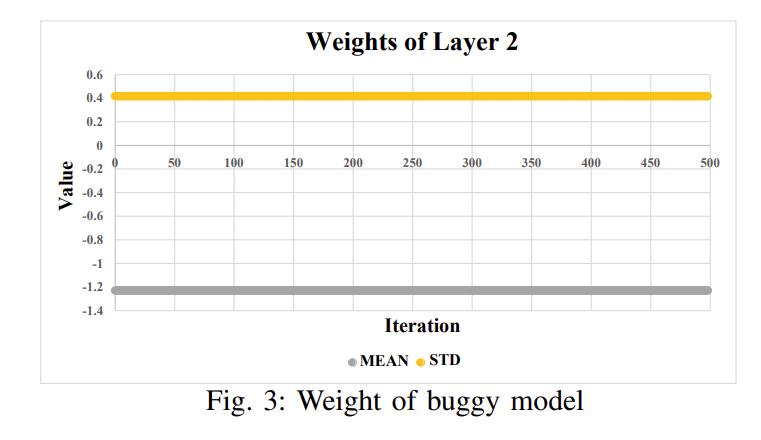
1)不正确学习率:根据损失函数得到的损失值,反向传播对权重进行微调是很重要的。在反向传播过程中,学习率对权值的更新有影响。在反向传播过程中,学习库迭代计算梯度下降。我们的关键观点是,在训练过程中,正确模型中权重的均值和标准差是不断变化的。相比之下,小车模型中权重的均值和标准差是恒定的。如果学习率有问题,我们可以从输出层的梯度输出中检测出来。图2和图3显示了这种行为的一个示例。在图2中,权重在正确的模型中应该变化,而在图3中,权重是恒定的,表明存在潜在的错误。为了利用这种洞察力,我们计算梯度输出的平均值和标准差以及每层的权重参数。
2)输入数据不正确:在某些情况下,训练数据没有正确归一化。例如,在MNIST模型中,像素应该在[- 1,1]范围内,而不是[0,255]。此外,训练数据可能具有NaN值,而开发人员忘记调用assert函数来检查是否存在NaN。在前向阶段,我们检索每年应用激活函数之前/之后的输出。然后我们计算每一层输出的均值和标准差。我们将检查应用激活后/之前的第一层输出是否有数值误差,如NaN或Inf。我们检测这种误差的第二种方法是计算第一层输出的平均值等于零的频率。一旦我们观察到异常值,我们将报告错误发生在哪一层,是在激活函数之前还是之后。
3)不正确的激活/损失函数:完成正向阶段后,我们计算损失和精度。有两个指标表明该模型存在问题。首先,如果两个指标中的一个有一个数值误差,如inor NaN。其次,经过一定的迭代后,损失反而开始增加,或者精度开始下降。
# E.DNN故障定位算法

算法1给出了我们的DNN故障定位算法。
在其核心,它通过在学习过程中插入分析和错误检查来增强DNN学习算法。它有三个目的:(1)确定深度学习程序是否包含错误;(2)报告故障位置,深度学习程序在哪个层、哪个阶段(前向传播和后向传播)存在bug;(3)上报失败信息,在迭代中,学习停止。它将训练数据集(包括输入和标注)、翻译后的命令式程序以及DNN参数(批大小和epoch)作为输入。如果发现了错误,则输出一条消息,包括错误的故障位置和失败信息.
在第1行,我们定义了两个列表来存储每次迭代中的loss和accuracy值。第2行表示我们对整个训练数据集进行了多少次迭代。
在训练过程中,训练数据集被分成几个较小的批次。例如,如果模型有2000个训练样例,分为500批,则模型需要4次迭代才能完成一个epoch。第3行显示了批大小的划分。第4-29行对训练数据集中的每个批次运行。在第5-11行,算法对前进阶段进行动态分析,在第24-29行,对后退阶段进行分析。在我们的回调函数中,重写方法on_train_batch_end(self, batch, logs=None)将在每个批处理结束时执行,并在前/后阶段执行动态分析,在检索激活函数,loss, accuracy,更新权重和梯度之前/之后的每一层的值。
1)前馈阶段:在第6行,算法在应用激活函数之前计算前馈层的输出。在第8行,我们在应用激活函数后计算输出。然后,我们调用ANA()过程来确定输出是否包含数值错误。在第12行,我们计算损失,并且确定第13行是否有任何数字错误。如果这里没有检测到错误,我们将每次迭代的loss值保存在第14行。在第15行,我们计算精度,并检查16-18行的精度是否有数值错误。如果这里没有检测到错误,我们在第19行保存训练期间的准确度值。在第20-22行,算法检查丢失是否在很长一段时间内没有减少,准确性是否在增加。在这两种情况下,算法计算斜率来比较当前步骤的损失/精度与至少比当前步骤落后num步的步骤的损失/精度。在这种情况下,算法报告一条消息MDL,表明模型没有学习。否则,继续训练。
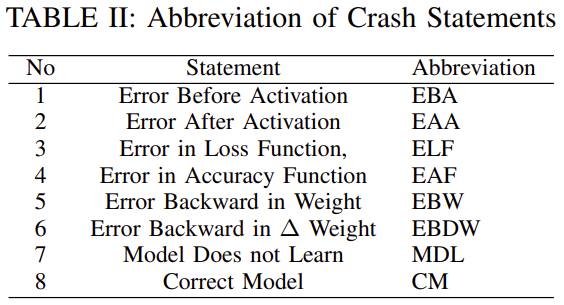
如表2所示,EBA表示Error Before Activation, EAA表示Error After Activation, L表示故障层号。
如表2所示,ELF表示损失函数中的Error。
2)反向传播阶段:在此阶段,算法收集每次迭代中每一层的权值和∆权值。在第25行,Weight和∆Weight是反向传播的输出。在第26行,算法调用ANA()过程并传递∆weight来检查是否有数值错误。如果∆权重有任何错误,算法将打印错误信息,并确定是哪一层导致了这个问题(第26行)。以同样的方式,在第27行,算法可以通过调用ANA()过程来确定每个层中的权重是否存在问题。如果过程确定权重存在问题,则算法将返回提示存在错误的消息.
最后,如果模型没有问题,算法将在第32行完成训练后终止,并打印此消息Correct model (CM)。
在第7、9、26和27行调用ANA(),以根据从检测获得的当前值确定错误是否发生。当DNN不学习时,可能会出现以下症状:(1)权重更新,∆权重不正确,(2)损失或精度没有以正确的尺度测量,(3)损失没有减少,迭代次数后精度没有增加。检查在ANA()中进行。
这个过程需要三个参数:输入值,层数和位置。由于ANA()在代码中的不同位置被调用,因此位置跟踪该值是来自前馈(FW)、后向(BW)传播还是权重(WT)传播。第2行定义了一组列表来存储每个层的每个位置的平均值。第3行计算输入的平均值。在第4行,该过程将检查平均值是否报告NaN或inf。此外,该过程将检查平均值在第5行是否等于零;如果是,那么我们计算每一层的所有值出现零的频率。如果0的数量大于阈值(第7行),则检测到错误,并且过程将返回true.
在第11行,我们将平均值存储在列表中。最后,该过程将从列表中返回最后N个元素作为切片,以检查最后N次迭代的平均值是否改变。

从图2和图3中,我们可以观察到模型在每次迭代中继续学习平均值是否在变化。如果存在数值错误,此过程将返回true;否则,返回false。
# Ⅳ. 表示评估
在本节中,我们的目标是回答以下研究问题:
•RQ1(验证):我们的技术能否有效地发现深度学习程序中的错误?
•RQ2(比较):与Keras库中现有的方法相比,我们的技术定位故障的效率和速度有多快?
•RQ3(限制):在哪些情况下,我们的技术无法报告bug并定位故障?
# A.实验配置
1)实现:为了执行我们的实验和评估,我们使用Python和Keras实现了我们的技术。
我们基于翻译的工具支持Dense, Dropout, Maxpooling, Convolution, BatchNormalization和Padding图层。此外,它还支持流行的优化方法、损失和激活函数。我们遵循机器学习参考文献[25]-[27],并使用Keras文档来实现compile(), sequential()和fit()函数的简化和仪器化版本。我们的基于回调的工具支持Keras支持的所有层和优化方法。
我们设置阈值= 1/4 * No。对于我们的工具和回调函数,在ANA()函数的第6行和第12行分别进行迭代和N= 50。根据我们的经验,这些设置最有助于在训练期间检测错误。
2)基准构建:我们从Stack Overflow帖子和GitHub提交中收集bug模型来构建基准。在Stack Overflow中,我们选择得分≥5且包含有bug的Keras代码的帖子。我们使用关键字“错误”、“bug”和同义词来搜索帖子。在第二步中,我们手动查看检索到的帖子,并删除所有包含部分代码的帖子。在第三步中,我们通过检查帖子是否提供了训练数据或使用了现有的已知训练数据来应用第二个过滤器。在最后一步中,我们研究了Stack Overflow中与post id对应的所有答案,使用了先前研究深度学习模型的bug修复模式的工作[10]中的方法。我们考虑可接受的质量指标,并选择得分最高的答案。我们分析了每个问答,并为每个帖子导出了故障位置和修复错误的补丁。我们总共获得了30个职位。
我们还挖掘GitHub提交来收集有bug的模型。
这个过程包括三个步骤。首先,我们搜索所有Keras存储库。之后,我们挖掘标题包含上述Stack Overflow挖掘过程中使用的关键字的所有提交。然后,我们只取最后一个版本修复,并手动检查提交是否与结构错误相关,从这些提交中,我们导出故障位置和修复错误的补丁。在最后一步中,我们检查存储库是否提供了训练数据。因此,我们随机选择了11个具有训练数据集的可执行程序。
例如,图4显示了我们为Stack Overflow post #[22]派生的补丁。表IV和表V给出了我们的基准,以及修复前后的参数总数、代码行数、损耗和精度。我们的工具和基准测试可以下载[21]。

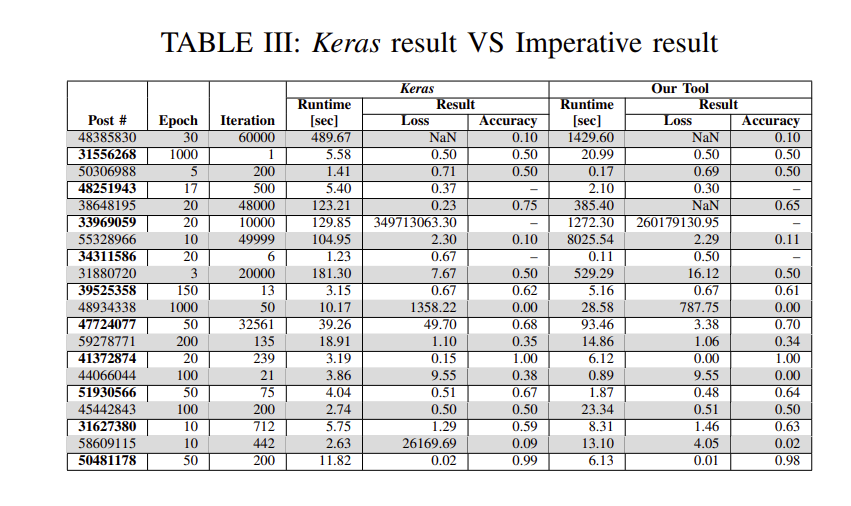
表III显示了原始Keras代码和命令式代码在准确性、损耗和运行时方面的比较。在所有基准测试中,与Keras相比,我们的命令式代码具有相当的准确性和损失。这个小偏差是由于在Keras代码中应用了额外的优化。在运行时方面,在训练和测试阶段,我们的命令式代码的执行时间是Keras的5倍。这背后的原因是命令式代码为识别bug及其根源所做的额外工作。我们的代码还能够在发现错误时尽早终止,并且在稍后的结果中,我们表明我们可以比Keras回调方法更快地检测到错误。
所有实验都在一台搭载Intel(R) Core (TM) i7-6500U、2.5 GHz处理器、16gb RAM、64位Windows 8.1操作系统的计算机上进行。
# B.结果与分析
表四:基准,我们显示(Post #) Stack Overflow的Post id,参数#,代码行,(Result Before Fix)应用补丁前的损失和精度,(Result After Fix)应用补丁后的损失和精度值
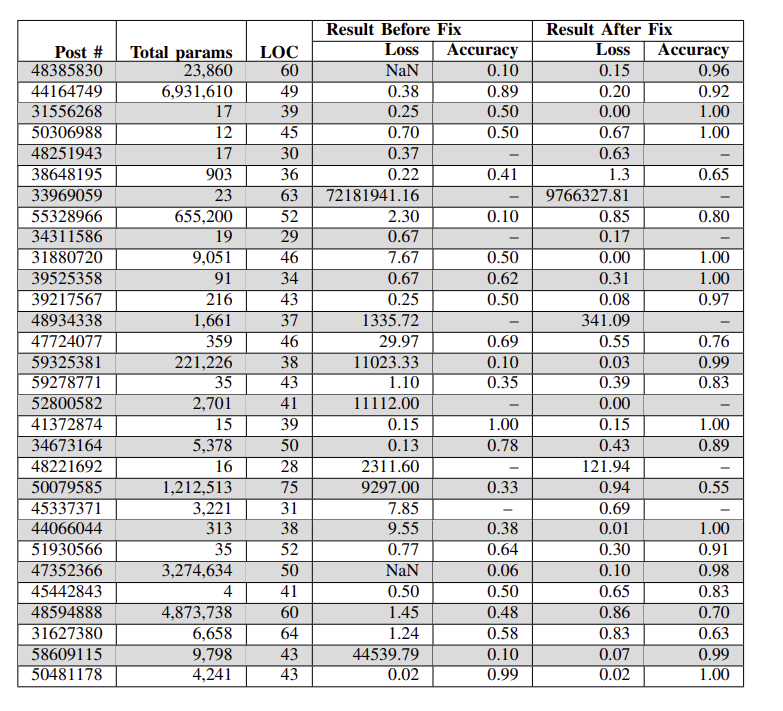
表5:基准测试,我们显示(GH j Ref) GitHub存储库引用的参数数量,代码行(LOC),(修复前的结果)应用补丁前的损失和精度值,以及(修复后的结果)应用补丁后的损失和精度

在表VI和VII中,第一列分别报告了带有相应链接的Stack Overflow post#和GitHub存储库参考。为了将我们的结果与Keras方法生成的结果进行比较,我们列出了Time、Epoch、Iteration、IB和FL列,分别表示该方法查找错误所需的时间、报告错误的时间和迭代次数、该方法是否正确识别错误以及该方法是否成功报告错误的故障位置。在IB和FL中,X表示方法成功,X表示失败,并且–无法识别或故障
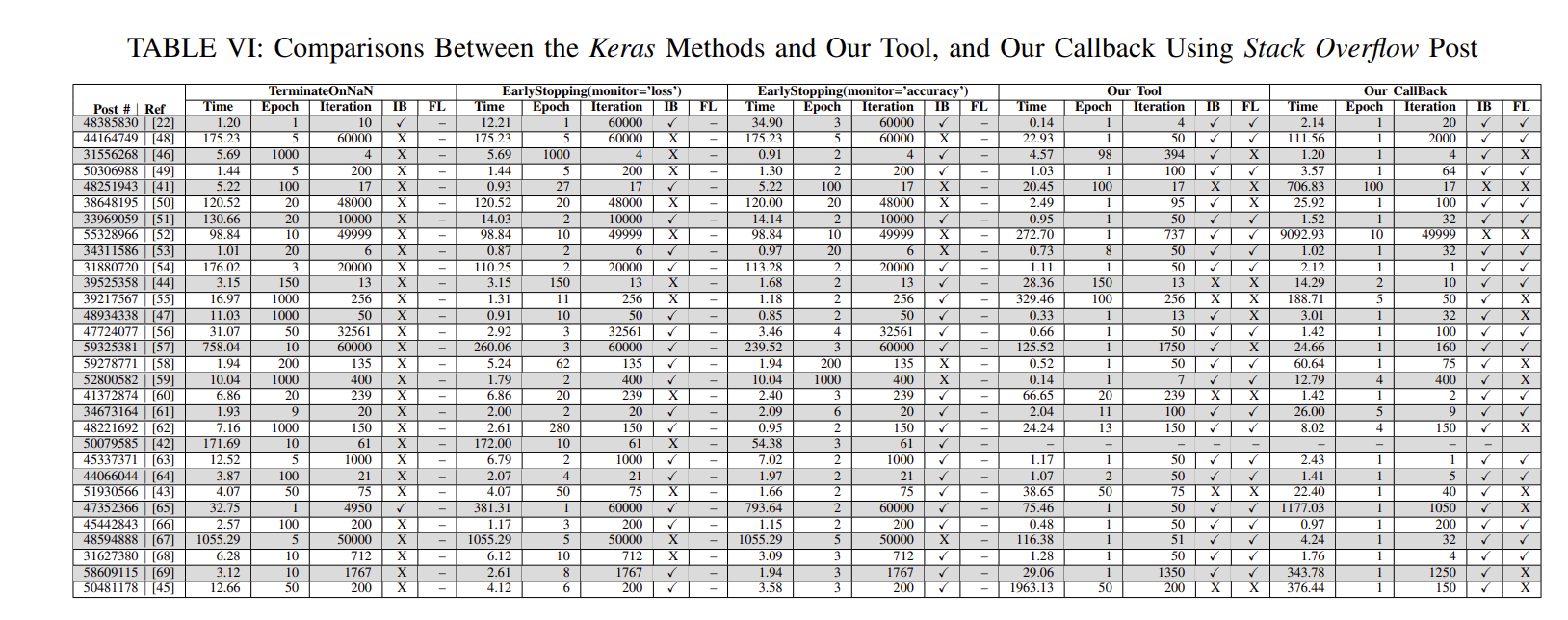
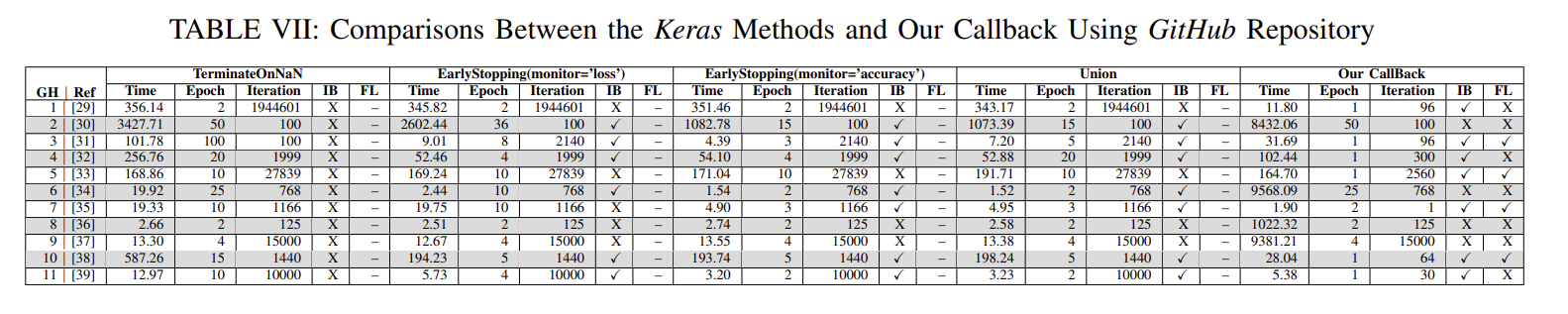
结果表明,我们的工具能够识别出29个错误程序中的23个错误,我们的回调函数能够识别出40个错误程序中的34个错误。相比之下,TerminateOnNaN(), earlystopped (' loss '), earlystopped (' accuracy ')和三个Keras方法一起能够分别识别40个错误中的2个,24个,28个和32个。这主要是因为与其他三种方法相比,我们的技术使用了更广泛的重要运行时值进行分析,而其他三种方法只使用一个度量,如损失或准确性。此外,早期停止(“损失”)和早期停止(“准确性”)有时不能很好地指示模型有问题。例如,深度神经网络可能会在某个值接近全局最小值的点上陷入局部最小值[40]。
在使用我们的工具的30个模型中,我们未能检测到7个模型的bug。我们的工具不能识别预测错误标签的错误模型。在程序[41]中,训练数据在[−1;+ 1]。这个模型有一个问题,所有的负值都被预测为零,因为开发人员在最后一层使用了ReLU激活函数,而不是在相同的输出标签范围(如TanH)中产生输出的激活函数。
在程序[42]中,使用fit_generator()代替fit(),我们的技术还不支持。
使用Fit_generator()对逐批生成的数据进行模型训练[28]。我们的技术还不支持这个API,我们计划在未来的工作中讨论和研究其他API。
在Stack Overflow post[43]中,用户询问了两个模型之间的差异,每个模型都有不同的输入维度,两个模型都是正确训练的,但不同的是在性能上。在这种情况下,我们的工具将不会发现任何数字错误或错误行为来检测错误。
在我们的工具中,我们没有针对以下问题:(1)缺乏数据集;(2)具有分布问题的训练数据集;(3)不正确的epoch数、批大小、隐藏层数和层中的神经节点数。这些问题的一个例子可以在程序中找到[44],[45],这些问题使模型在早期阶段终止训练,我们的工具不会检测到模型中的问题。
我们还将我们的方法与三种Keras方法在故障定位方面进行了比较,我们发现三种Keras方法都无法确定根本原因。我们的工具能够确定29个程序中的19个程序的根本原因,我们的回调能够确定40个程序中的21个程序的根本原因。我们将我们的工具和回调方法的结果与我们为基准构建的基本事实进行了比较。我们的工具可以在29例中精确地确定19例导致错误的层或参数,我们的回调方法可以在40例中精确地确定21例。在其他模型中,该工具和回调方法报告了另一层的根本原因,因为训练过程是一个循环;一层的操作会影响相邻层。例如程序[46],使用mean_absolute_error作为损失函数而不是mean_squared_error,使用SGD优化器而不是Adam优化器。我们的工具报告这个错误是EBW(反向传播中的权重错误)。No = 1。在程序[47]中,用户指定学习率= 0.1,而不是学习率= 0.001。我们的工具报告了EBA(激活前错误函数),层。No = 2。
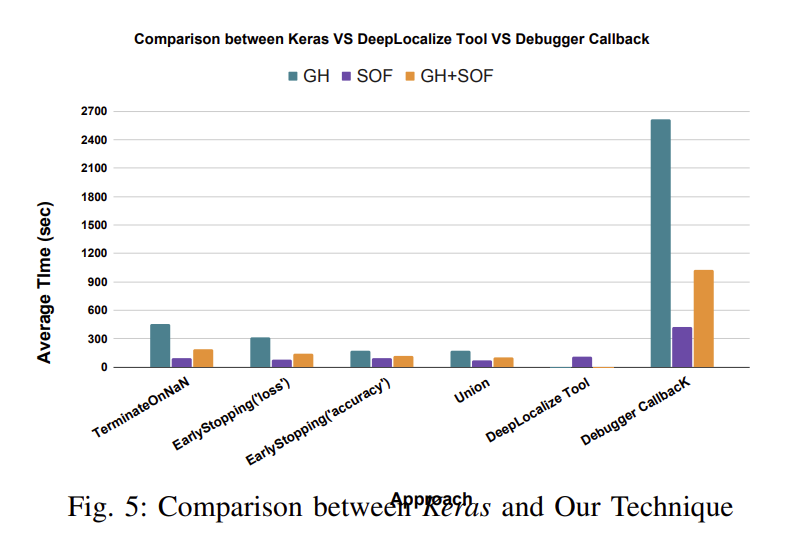
我们使用Stack Overflow (SOF)和GitHub (GH)基准测试来测量三个Keras方法、我们的工具和我们的回调函数的分析时间。使用SOF基准,TerminateOnNaN(), earlystop (' loss '), earlystop (' accuracy '),三个Keras方法一起,我们的回调方法和我们的工具在所有堆栈溢出(SOF)基准测试中分别平均耗时93.01,78.98,93.04,73.55,421.39和107.99秒。而在GH基准测试中,TerminateOnNaN(), earlystop (' loss '), earlystop (' accuracy '),三个Keras方法加在一起,我们的回调平均分别为451.52,310.57,171.22,172.02和2613.6秒。对于四个相应的工具,所有Stack Overflow (SOF)和GitHub (GH)基准测试的平均时间分别为191.6秒、142.67秒、114.54秒、100.63秒和1024.25秒。在图5中,我们绘制了平均时间,并显示,当损失值中存在NaN时,TerminateOnNaN()终止程序;在其他情况下,培训将继续进行。这就是为什么它比其他方法需要更长的时间。
我们的回调函数需要比三个Keras方法更多的值,例如更新权重和梯度来执行动态分析。如果模型有大量的参数,这将导致开销,但是与使用其他回调函数的时间相比,这个开销通常是微不足道的。然而,我们预计手动调试和故障定位所需的时间将远远超过执行回调函数所需的时间。
在从Stack Overflow和258 GitHub构建基准测试并使用我们的技术识别错误的过程中,我们观察到开发人员最常见的错误是(1)选择激活和丢失函数,因为有许多组合可以选择激活和损失,这取决于问题的类型,(2)选择超参数,如学习率,层中神经节点的数量、模型中的层的数量以及(3)对训练数据集进行预处理,例如,MNIST模型需要将训练数据集从[-256,+256]到[-1,1]的范围归一化。如果没有故障定位信息,开发人员将面临确定导致模型中错误的层或参数的问题。
# C.总结
RQ1(验证):我们提供了经验证据(表III),证明使用我们的命令式程序训练DNN与使用Keras库是一致的。对于RQ1,我们展示了我们的工具能够识别29个错误模型中的23个,我们的回调函数能够识别40个错误模型中的34个。此外,我们的技术能够使用我们的工具精确地确定29个错误中的19个,使用我们的回调函数精确地确定40个错误中的21个,而Keras无法对错误进行本地化。
RQ2(比较):我们的技术能够使用我们的回调函数识别40个错误模型中的34个,使用我们的工具识别29个错误模型中的23个。另一方面,Keras库分别报告了40个模型中的2个、24个和28个的bug。同样,如果我们对三个方法进行联合,Keras库报告了40个模型中的32个模型的bug。我们还表明,我们的技术可以有效地定位40个程序中的21个程序使用我们的回调和29个程序中的19个程序使用我们的工具的根本原因,而Keras方法不支持此功能。如图5所示,通过识别错误,我们使用动态分析的工具比Keras更实用、更快。使用Keras的三种方法分别平均耗时191.6、142.67和114.54秒,而我们的工具平均耗时107.99秒。另一方面,我们的回调需要更多的时间来动态分析额外的参数,而不是损失和准确性。与TerminateOnNaN()所花费的时间相比,这个开销通常是微不足道的。
RQ3(限制):使用我们的工具,我们在30个程序中检测不到7个程序的bug,在30个程序中无法定位11个程序的错误,在41个程序中我们的回调无法定位20个程序的错误。这些程序要么预测了错误的标签,要么在训练数据集、epoch的设置、批大小、隐藏层的数量和神经节点的数量方面存在问题。在这种情况下,训练在模型完成学习之前就停止了。因此,我们的工具无法处理这些情况。此外,我们的原型并不支持所有的Keras api。例如,Stack Overflow[42]中的一个bug程序使用了fit_generator()而不是fit()函数。使用Fit_generator()对逐批生成的数据进行模型训练[28]。我们计划在未来的工作中涵盖和研究其他api。
# Ⅴ. 讨论对有效性的威胁
我们主要关注可能影响评估和结果的工具的实现。为了最小化这种威胁,我们遵循Keras代码[70],并仔细检查作者之间的实现,以减少将主要错误与我们针对Keras的工具进行比较的机会,如表3所示。
我们的工具目前处理Keras库中常见的层/ api,包括:Dense, Dropout, MaxPooling2D, Conv2D和BatchNormalization。我们可能还无法处理与其他api相关的深度学习程序,例如ConvLSTM2D(), Conv3D()。
我们使用创建的基准测试验证了工具的输出。手动创建的基准的可靠性可能会威胁到我们结果的有效性。为了减轻这种威胁,我们在之前的工作中采用了相同的方法[13]。
此外,我们在修复模型中的问题之前/之后对基准进行了评估。
# Ⅵ. 讨论相关作品
在技术思想方面最接近的相关工作是Gopinath等人[20],[24]。Gopinath等人提出了一种受程序分析启发的新方法(DeepCheck),该方法使用符号执行来测试深度神经网络(DNN)。
DeepCheck还使用白盒技术来启用符号执行来查找重要像素,并通过将DNN转换为具有与DNN相同行为的命令式程序来查找攻击像素。使用MNIST数据集进行的实验结果表明,他们的方法能够通过找到DNN无法正确分类的最重要像素来创建1像素和2像素攻击。我们的命令式表现受到了这件作品的启发。虽然这项工作的重点是识别对抗性攻击,但我们的工作旨在识别dnn中的故障并定位其故障。
# A.测试深度神经网络
DeepTest[71]和后续工作旨在自动生成测试用例,以检查与现实世界输入相对应的角落用例。这些工作集中在测试用例的生成上,而我们的工作使用现有的训练数据集,并通过观察深度神经网络的运行时行为来定位bug的根本原因。
Zhang等[72]对这一领域的工作进行了全面调查。Eniser等[73]在基于谱的故障定位的启发下,提出了一种新的白盒分析技术(DeepFault)。DeepFault测试DNN模型以实现两个目标:(i)检测可疑神经元,即可能对DNN性能不足负有更大责任的神经元;(ii)合成新的输入,使用正确分类的输入,锻炼已识别的可疑神经元。在MNIST和CIFAR-10数据集上进行的实验结果表明,DeepFault可以有效地识别可疑神经元。
DeepFault不关注结构错误,而是关注训练错误,以及给定特定测试集的预训练dnn分析。而我们的工具识别错误的模型和错误的深层神经网络结构错误的根本原因
# B.深度学习漏洞的实证研究
已经有一些实证研究分析了深度学习网络中不同类型的bug。这些研究是在Stack Overflow帖子和GitHub问题的真实代码和示例上进行的。他们专注于漏洞的症状和根本原因,以更好地理解深度学习漏洞。
Zhang等人[8]利用Stack Overflow帖子和GitHub提交来研究基于TensorFlow构建的深度学习应用程序中的bug。他们专注于TensorFlow漏洞的症状和根本原因,以更好地理解深度学习漏洞。Islam等人[9]也使用Stack Overflow问题和GitHub提交研究了深度学习漏洞。
他们还为五个流行的深度学习库对深度学习软件的bug类型、根本原因和bug影响进行了分类。
Islam等人[10]进行了另一项研究,以了解bug修复模式以及开发人员如何开发工具来自动修复bug。他们对来自Stack Overflow的415篇文章和来自GitHub的555篇关于5个流行的DNN包的提交进行了全面的研究,以了解错误修复模式,以及如何修复DNN软件中的错误。本研究的主要目标是帮助开发人员了解bug的特征,以及他们如何设计一个自动修复工具
# C.深度学习中的bug修复
近年来,有几种关于调试深度神经网络的建议。这些技术通常受到软件调试和测试技术的启发。
Ma等人[74]在软件调试的启发下,提出并开发了MODE技术。MODE执行状态差分分析来解决两类问题:过拟合问题和欠拟合问题。MODE可以通过识别模型中导致错误分类的错误特征(或神经元)来解决这些问题,然后构造特征的重要程度,用新的输入样本选择来重新训练错误的神经元。MODE提供了一种有效的方法来修复有bug的模型,而不会引入新的bug,并且在准确性和训练时间成本上做出了妥协。
Zhang等人[75]引入了一种自动修复深度学习模型的方法,称为Apricot。杏能够在不使用额外训练数据或任何人工参数的情况下调整训练不良的权重,杏使用原始模型的一组约简模型,并迭代比较原始模型与约简模型的正确/不正确之间的差异,以找到导致原始模型中错误分类的失败测试用例。该方法采用三种策略来调整权重,以达到更高的测试精度。使用CIFAR-10数据集和五个最先进的深度学习模型进行的实验结果表明,该方法可以提高测试和训练的准确性。
近年来,一些研究人员支持深度神经网络的自动调试和修复方法,最近的研究总结在[72]。这一课题尚处于早期阶段[74],[75]。据我们所知,以前所有的工作都集中在训练bug上。我们的技术是第一种通过应用DNN漏洞检测算法自动识别漏洞模型并定位DNN中结构漏洞的根本原因的方法。
# Ⅶ. 总结
随着深度神经网络与不同领域的软件系统的集成,开发调试技术来定位错误的根本原因变得迫在眉睫。因此,最近的工作开发了检查整个模型并发现故障的技术。受程序分析和软件调试技术的启发,我们提出了一种由动态分析和统计分析驱动的自动化方法。它可以帮助识别有缺陷的模型和DNN错误的根本原因。使用40个真实深度学习应用程序的实验评估显示了我们的技术的有用性。对于34/40个案例,我们的方法能够检测到错误,而Keras提供的最佳调试方法检测到32/40个错误。我们的方法能够定位21/40个bug,而Keras无法定位任何错误。
未来的工作包括开发修复深度神经网络错误的技术,并探索我们的工作无法检测故障(6/40)和定位错误(19/40)的情况。
最近的工作也使用DNN结构分析将其分解为模块[76]。探索是否可以利用类似的机制进行更好的本地化将是一件有趣的事情。除了准确性错误之外,检测和定位更多的非功能性错误也很有趣,例如公平性错误[77]。